네트워크 I/O 모니터링 확장
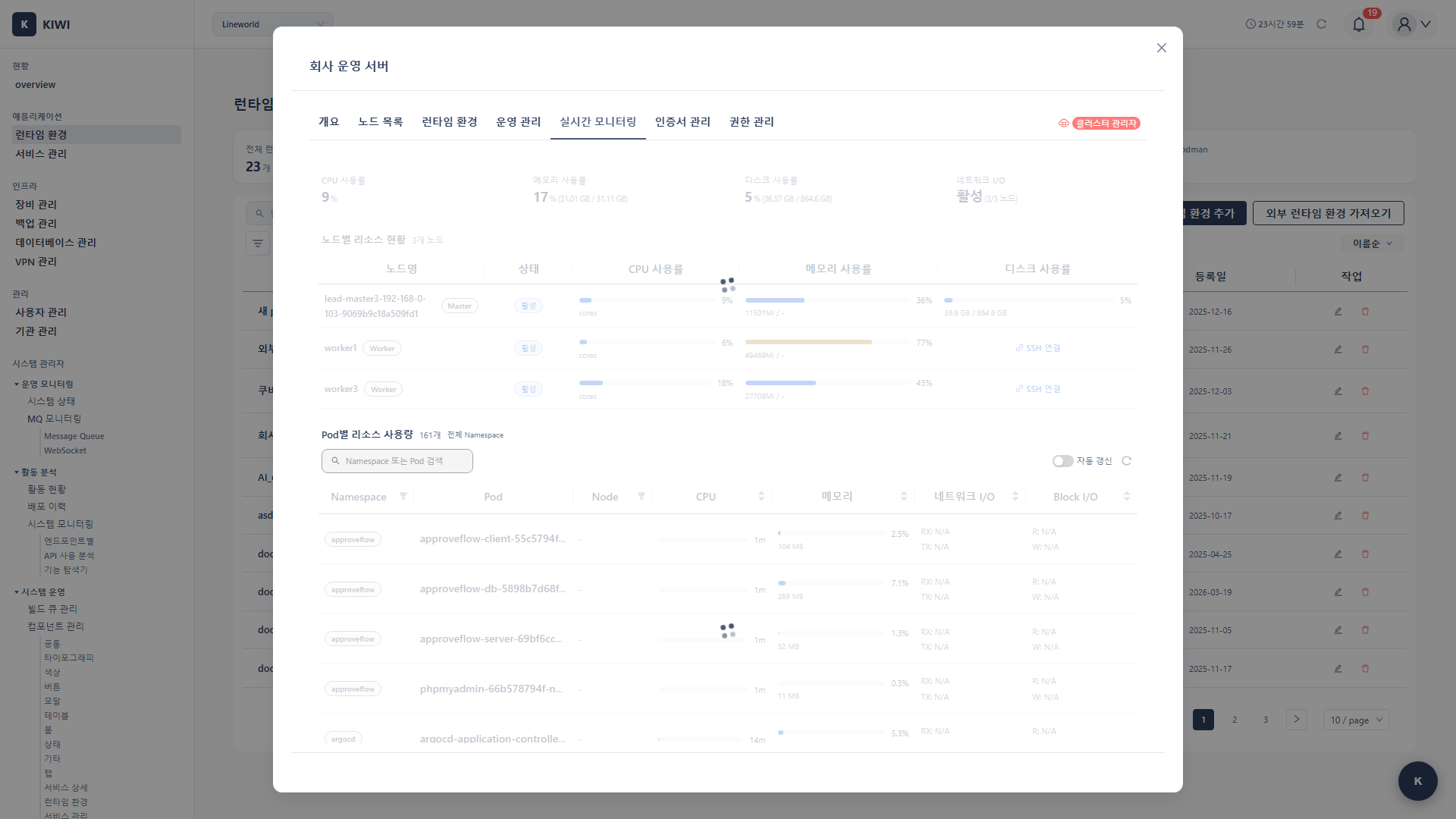
Metrics Server는 CPU/메모리 사용량은 제공하지만 네트워크 I/O 메트릭은 제공하지 않습니다. 컨테이너별 네트워크 사용량이 필요하다면 네트워크 I/O 모니터링 확장 을 설치하세요.
- Container별 네트워크 송수신량을 확인하고 싶을 때
- 네트워크 병목이 의심되어 Pod별 트래픽을 분석하고 싶을 때
모니터링 구성요소
Metrics Server vs 모니터링 확장
각 도구의 역할과 특징을 비교해 보겠습니다.
- Metrics Server: CPU/메모리 리소스 메트릭을 제공합니다. HPA와
kubectl top명령에 사용됩니다. KIOPS의 CPU/메모리 사용량 표시는 모두 Metrics Server를 통해 수집됩니다. - cAdvisor: 경량(lightweight) 옵션으로, 각 노드의 컨테이너 리소스 및 네트워크 메트릭을 수집합니다. 권장 옵션입니다.
- Prometheus Stack: 표준(standard) 옵션으로, kube-prometheus-stack 차트를 설치하여 메트릭 수집과 쿼리, 장기 저장이 가능합니다. 고급 사용자용입니다.
KIOPS의 네트워크 I/O 모니터링 확장 모달에서는 cAdvisor 또는 Prometheus Stack 중 하나만 라디오 버튼으로 선택하여 설치합니다. 두 가지를 함께 설치하는 흐름은 제공되지 않습니다.
사전 요구사항
- Kubernetes 클러스터가 KIOPS에 등록되어 있어야 합니다.
- 클러스터 마스터 노드에 Helm이 설치되어 있어야 합니다.
- 충분한 클러스터 리소스 (Prometheus Stack 설치 시)
권한 안내: 이 기능에 접근할 수 없다면 기관 관리자에게 권한을 요청하세요.
Step 1: 실시간 모니터링 탭 이동
- [런타임 환경] 페이지에서 대상 클러스터를 선택합니다.
- 클러스터 상세 페이지에서 실시간 모니터링 탭을 클릭합니다.
- 네트워크 I/O 모니터링 확장 버튼을 클릭하여 모달을 엽니다.
Step 2: 사전 검증 (12개 항목)
모달이 열리면 다음 12가지 항목이 자동으로 점검됩니다.
- connection: 마스터 노드 SSH 연결 가능 여부
- commands: 필수 명령(kubectl, helm 등) 존재 여부
- kubernetes_version: 지원되는 Kubernetes 버전인지 확인
- helm_installed: Helm 설치 여부 (Prometheus Stack 선택 시 필수)
- available_memory: 사용 가능한 메모리 충분 여부
- available_disk: 사용 가능한 디스크 공간 충분 여부
- namespace_permission: 네임스페이스 생성 권한
- cluster_permission: 클러스터 리소스 생성 권한
- network_access: 컨테이너 이미지 다운로드를 위한 네트워크 접근
- storage_class: 사용 가능한 StorageClass 존재 여부
- node_count: 노드 수 확인
- existing_installation: 기존 설치 여부 확인
사전 검증 결과의 recommended_option 값에 따라 라디오 버튼의 기본 선택이 자동으로 설정됩니다. 일반적으로 리소스가 부족하거나 단순한 환경에서는 cAdvisor가, 충분한 리소스와 Helm이 준비된 환경에서는 Prometheus Stack이 추천됩니다.
Step 3: 설치 옵션 선택
사전 검증 통과 후, 다음 두 가지 라디오 옵션 중 하나를 선택합니다.
- cAdvisor 설치 (lightweight, 권장): 경량 옵션. 각 노드에 DaemonSet으로 cAdvisor를 배포하여 컨테이너 메트릭을 수집합니다.
- Prometheus Stack 설치 (standard, 고급): 표준 옵션. Helm으로 kube-prometheus-stack 차트를 설치하여 Prometheus, Grafana, Alertmanager 등을 함께 구성합니다.
각 옵션 선택 시 필요한 리소스(권장 메모리/디스크 등)는 requirements 텍스트 로만 표시됩니다. CPU/메모리/스토리지를 직접 입력하는 UI는 제공되지 않습니다. 또한 보존 기간, 알림 규칙(Slack/Email/Webhook) 등의 설정 UI도 제공되지 않습니다.
Step 4: 설치 실행 (5단계)
설치 시작 버튼을 클릭하면 백엔드가 다음 5단계로 설치를 진행합니다.
- prepare: 사전 준비 작업 수행
- namespace: 모니터링 전용 네임스페이스 생성
- helm_repo: Helm 리포지토리 추가 (Prometheus Stack 선택 시)
- install: 컴포넌트 설치 (cAdvisor DaemonSet 또는 Helm 차트)
- verify: 설치 검증
선택한 옵션에 따라 일부 단계가 생략되거나 다르게 동작할 수 있습니다. 예를 들어 cAdvisor 옵션은 helm_repo 단계가 적용되지 않을 수 있고, Prometheus Stack 옵션은 모든 5단계가 실행됩니다.
백그라운드 실행 지원
설치 중 모달을 닫아도 백엔드 job은 계속 실행됩니다. 나중에 모니터링 탭으로 돌아오면 진행 상태와 결과를 확인할 수 있습니다.
설치 상태 확인
상태 표시
모니터링 탭에서 각 구성요소의 상태를 확인할 수 있습니다:
- 미설치: 해당 모니터링 구성요소가 아직 설치되지 않은 상태입니다.
- 설치 중: 설치가 진행 중인 상태입니다. 일반적으로 1-3분 정도 소요됩니다.
- Running: 구성요소가 정상적으로 작동 중입니다.
- Error: 구성요소에 오류가 발생했습니다. 필요시 재설치를 시도하세요.
실시간 메트릭 확인
설치 완료 후 KIOPS에서 확인할 수 있는 메트릭:
노드 수준 (Metrics Server + 확장):
- CPU 사용률 (%) — Metrics Server 제공
- 메모리 사용량 (GB / %) — Metrics Server 제공
- 네트워크 I/O — 모니터링 확장 제공
Pod 수준:
- 컨테이너별 CPU/메모리 사용량 — Metrics Server 제공
- 컨테이너별 네트워크 송수신량 — 모니터링 확장 제공
- 재시작 횟수
모니터링 확장(cAdvisor / Prometheus Stack) 설치 여부와 무관하게, CPU/메모리 사용량은 Metrics Server를 통해 수집 됩니다. 따라서 Metrics Server를 먼저 설치하는 것이 권장됩니다.
문제 해결
사전 검증 실패
- helm_installed 실패 (Prometheus Stack 선택 시): 마스터 노드에 Helm이 설치되어 있지 않습니다. 클러스터 관리자가 Helm을 설치한 후 다시 시도하세요. 또는 cAdvisor 옵션을 선택하면 Helm 없이 설치할 수 있습니다.
- available_memory / available_disk 실패: 리소스가 부족합니다. cAdvisor 옵션(경량)으로 변경하거나 클러스터 리소스를 확보하세요.
- storage_class 실패: 사용 가능한 StorageClass가 없습니다. 클러스터에 StorageClass를 먼저 생성해야 합니다.
cAdvisor 설치 실패
- DaemonSet 배포가 실패하는 경우: 노드에 충분한 리소스가 없어 cAdvisor Pod를 스케줄링할 수 없습니다. 노드 리소스 상황을 확인하세요.
- 이미지 Pull이 실패하는 경우: 클러스터 노드의 인터넷 연결 또는 프라이빗 레지스트리 설정을 확인하세요.
Prometheus Stack 설치 실패
- Helm 차트 설치 실패: 마스터 노드에서
helm repo list와helm list -A명령으로 상태를 점검하세요. - OOM(Out of Memory)이 발생하는 경우: 노드 메모리가 부족합니다. 더 큰 노드를 추가하거나 cAdvisor 옵션으로 변경하세요.
메트릭 수집 안됨
- 원인 1: cAdvisor/Prometheus Pod가 Running 상태가 아님
- 원인 2: 네트워크 정책으로 차단됨
해결 방법:
- Pod 상태 확인:
kubectl get pods -n monitoring - 로그 확인:
kubectl logs <pod-name> -n monitoring