HPA 자동 스케일링
HPA(Horizontal Pod Autoscaler)는 Kubernetes 런타임에서만 제공됩니다. Docker · Podman 런타임에는 자동 스케일링과 수동 스케일링 기능이 없습니다.
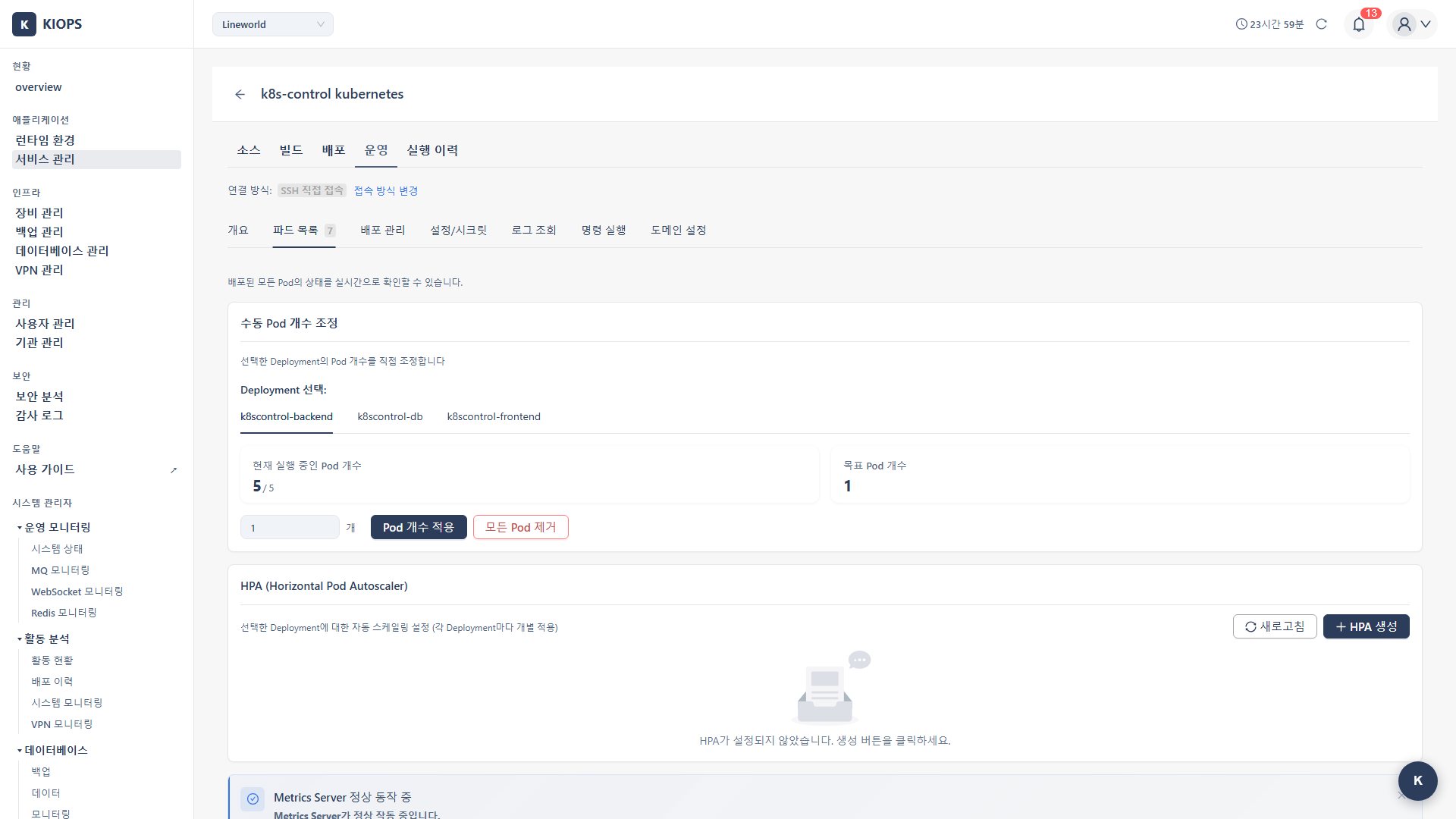
트래픽이 급증할 때마다 수동으로 스케일을 조정하는 것은 번거롭고 위험합니다. HPA(Horizontal Pod Autoscaler)를 설정하면 서비스 부하에 따라 Pod가 자동으로 확장/축소됩니다.
- 자동 대응: 트래픽이 늘면 자동으로 Pod가 추가됩니다.
- 비용 절약: 트래픽이 적을 때는 Pod를 줄여 리소스를 절약합니다.
- 안정성 향상: 수동 조작 실수를 방지합니다.
KIOPS에서 지원하는 HPA 범위
KIOPS의 HPA는 CPU 기반 자동 스케일링만 지원하며, 내부적으로 kubectl autoscale --cpu-percent 명령으로 생성됩니다. 메모리 기반 스케일링, 다중 메트릭, 커스텀 메트릭(Prometheus 등), 스케일 안정화 윈도우(stabilizationWindowSeconds), 스케일링 정책(Pods/Percent 유형·값·기간)은 지원하지 않습니다.
설정 가능한 항목은 다음 세 가지입니다.
- minReplicas: 최소 Pod 수 (기본값 1, 권장 2 이상)
- maxReplicas: 최대 Pod 수 (기본값 10)
- targetCPU(%): CPU 사용률 목표 (기본값 80)
작동 원리
[Metrics Server] → [HPA Controller] → [Deployment Scale]
↓ ↓ ↓
CPU 메트릭 수집 목표 CPU와 비교 Pod 수 조정
사전 요구사항
- Kubernetes 클러스터에 Metrics Server가 설치되어 있어야 합니다.
- 서비스가 K8s에 배포되어 있어야 합니다.
메트릭 서버가 없으면 메트릭 서버 설치 가이드를 참고하세요.
권한 안내: 이 기능에 접근할 수 없다면 기관 관리자에게 권한을 요청하세요.
HPA 생성
Step 1: 운영 모달 열기
- [서비스 관리] 페이지에서 대상 서비스의 Operate 단계를 클릭합니다.
- 운영 모달에서 파드 목록 탭으로 이동합니다.
Step 2: HPA 섹션 진입
- 파드 목록 탭의 HPA 섹션을 확인합니다.
- HPA 생성 버튼을 클릭합니다.
Step 3: 설정 입력
폼에는 다음 세 가지 항목만 입력합니다.
- minReplicas (기본값 1, 권장 2 이상): 부하가 낮아도 유지할 최소 Pod 수입니다. 고가용성을 위해 2개 이상을 권장합니다.
- maxReplicas (기본값 10): 부하가 높아도 확장할 수 있는 최대 Pod 수입니다. 클러스터 리소스와 비용을 고려해 설정합니다.
- targetCPU(%) (기본값 80): CPU 사용률이 이 값을 초과하면 Pod가 추가됩니다. 일반적으로 70~80%를 권장합니다.
Step 4: 생성
- 생성 버튼을 클릭합니다.
- KIOPS는
kubectl autoscale --cpu-percent명령으로 HPA를 생성합니다. - 이미 동일 Deployment에 HPA가 존재하는 경우, 기존 HPA를 삭제 후 재생성합니다.
HPA 카드 정보
생성된 HPA는 파드 목록 탭에 카드 형태로 표시됩니다.
- HPA 이름
- 대상 Deployment
- 최소/최대 Pod
- 목표 CPU(%)
- 현재 실행 Pod 개수
- 삭제 버튼
삭제 버튼을 누르면 HPA가 제거되고 수동 스케일링으로 전환됩니다.
HPA와 수동 스케일링의 관계
HPA가 활성화되어 있는 동안에는 수동 스케일링이 잠겨 있습니다. 백엔드에서도 kubectl scale 호출이 차단됩니다. 수동 스케일을 다시 사용하려면 먼저 HPA 카드의 삭제 버튼으로 HPA를 제거하세요.
실제 사용 시나리오
시나리오 1: 웹 애플리케이션
요구사항: 트래픽에 따라 자동 확장
설정:
- minReplicas: 2
- maxReplicas: 20
- targetCPU: 70%
시나리오 2: API 서버
요구사항: 빠른 확장과 안정적인 운영
설정:
- minReplicas: 3
- maxReplicas: 50
- targetCPU: 60%
시나리오 3: 배치 워크로드
요구사항: CPU 부하에 따라 점진적 확장
설정:
- minReplicas: 1
- maxReplicas: 10
- targetCPU: 80%
리소스 요청 설정
HPA가 정확하게 작동하려면 Pod의 **CPU 요청(requests.cpu)**이 설정되어야 합니다. HPA는 이 값 대비 사용률을 계산해 스케일링을 결정합니다.
리소스 요청 예시
resources:
requests:
cpu: "200m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"
이 설정에서 HPA targetCPU 70%는:
- 200m × 70% = 140m 평균 사용 시 유지
- 그 이상이면 스케일 업 트리거
메모리 limit은 OOM 방지용으로만 사용되며, HPA의 스케일링 기준으로는 사용되지 않습니다.
문제 해결
HPA가 스케일하지 않음
- 메트릭이 표시되지 않는 경우: Metrics Server가 설치되어 있지 않습니다. 메트릭 서버 설치를 진행하세요.
- Unknown 상태로 표시되는 경우: Pod에 CPU 요청(requests.cpu)이 설정되어 있는지 확인하세요. 요청이 없으면 HPA가 사용률을 계산할 수 없습니다.
- 목표값에 도달하지 않는 경우: 현재 CPU 부하가 낮아 스케일링이 필요하지 않은 정상 동작입니다.
과도한 스케일링
- 너무 많은 Pod가 생성되는 경우: targetCPU가 너무 낮게 설정되어 있습니다. 70-80%로 상향 조정하세요.
- 리소스 부족으로 Pod가 Pending 상태: maxReplicas에 도달했거나 클러스터 리소스가 부족합니다. maxReplicas 값을 조정하거나 노드를 추가하세요.
HPA 삭제가 필요한 경우
수동 스케일링이 필요하거나 설정을 변경하려면 HPA 카드의 삭제 버튼을 사용하세요. 동일 Deployment에 새 HPA를 생성하면 기존 HPA는 자동으로 삭제 후 재생성됩니다.
베스트 프랙티스
HPA를 효과적으로 사용하기 위한 권장 사항입니다.
설정 권장사항
- minReplicas: 2 이상 - 고가용성을 위해 필수입니다.
- targetCPU: 70-80% - 너무 낮으면 불필요한 비용이 발생합니다.
- CPU 요청(requests.cpu): 실제 사용량 기반 - HPA가 정확하게 동작하려면 필수입니다.
모니터링
HPA가 잘 동작하는지 정기적으로 확인하세요.
- 현재 Pod 개수 확인: 파드 목록 탭의 HPA 카드에서 현재 실행 중인 Pod 개수를 확인합니다.
- 최대 도달 알림: 자주 maxReplicas에 도달하면 maxReplicas를 상향하거나 리소스 요청을 검토합니다.
- 비용 모니터링: 스케일링에 따른 클라우드 비용을 추적합니다.
테스트
프로덕션 적용 전에 HPA 동작을 검증하세요.
- 부하 테스트: 트래픽을 증가시켜 스케일 업이 잘 동작하는지 확인합니다.
- 회복 테스트: 트래픽을 줄여 적절히 축소되는지 확인합니다.
- 한계 테스트: maxReplicas 도달 시 서비스 동작을 확인합니다.
HPA 설정을 프로덕션에 바로 적용하지 마세요. 스테이징 환경에서 충분히 테스트한 후 적용하세요.
HPA 비활성화
HPA를 제거하려면 파드 목록 탭의 HPA 카드에서 삭제 버튼을 클릭합니다. 삭제 후에는 수동 스케일링(Pod 개수 적용 / 모든 Pod 제거)을 다시 사용할 수 있습니다.