로그 모니터링
서비스에 문제가 생겼을 때 가장 먼저 확인해야 할 것은 바로 로그입니다. KIOPS의 로그 모니터링 기능을 사용하면 Pod와 컨테이너의 로그를 쉽게 조회하고 분석할 수 있습니다.
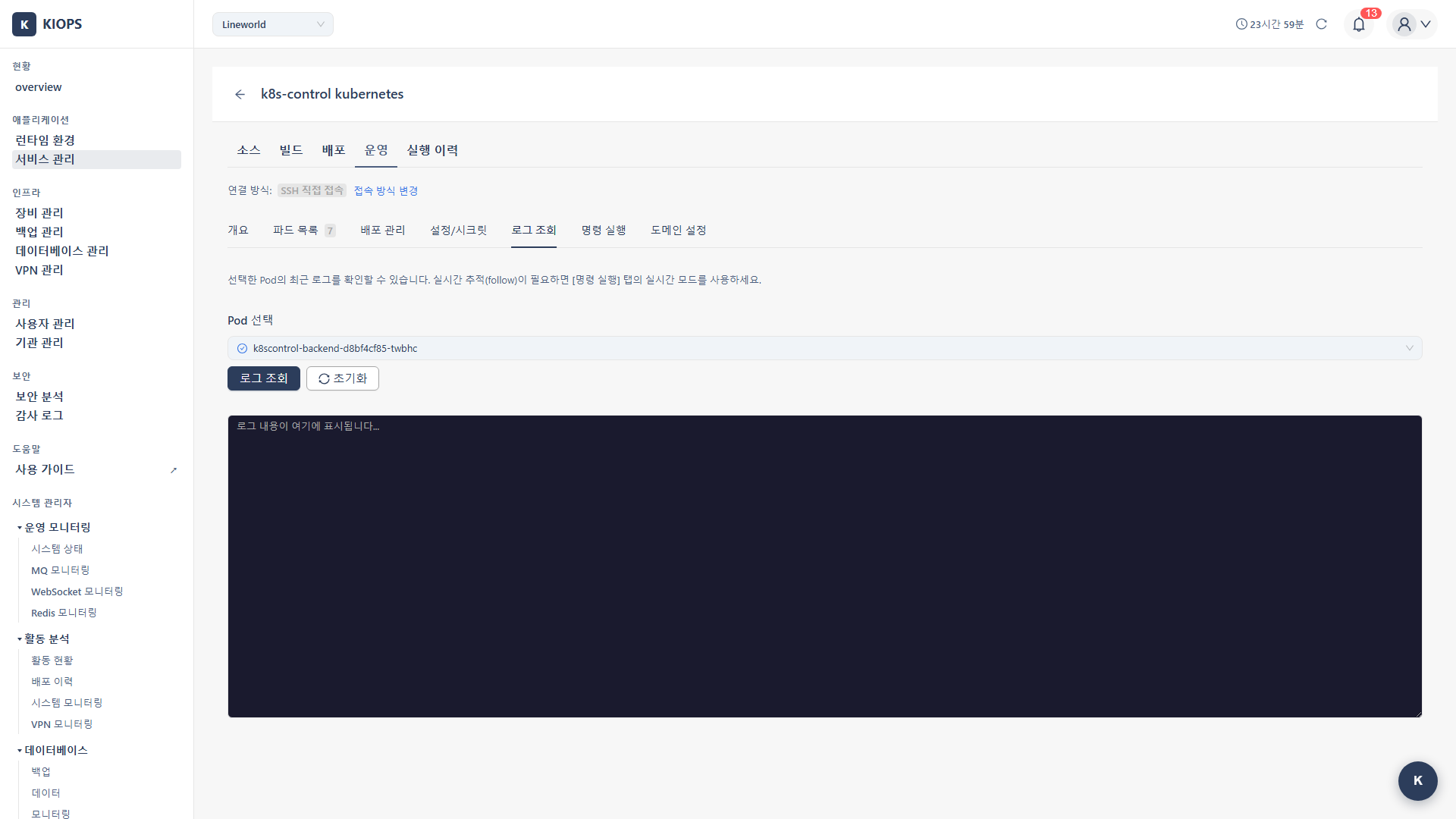
로그 조회 탭은 모든 런타임에서 제공되지만, 대상 선택 드롭다운이 다릅니다.
- Kubernetes: Pod 선택 드롭다운에서 대상 Pod를 선택합니다.
- Docker · Podman: 컨테이너 선택 드롭다운에서 대상 컨테이너를 선택합니다.
로그는 애플리케이션이 무슨 일을 하고 있는지 알려주는 "일기장"과 같습니다. 오류 메시지, 경고, 디버그 정보 등을 통해 문제의 원인을 빠르게 파악할 수 있습니다.
로그 조회 개요
KIOPS는 Kubernetes와 Docker/Podman 환경 모두에서 로그 조회를 지원합니다. UI는 인프라 타입에 따라 분기되며(isDockerInfra), Docker와 Podman 모두 동일한 인터페이스를 사용합니다.
- Kubernetes: Pod의 stdout/stderr를 가져옵니다.
- Docker/Podman: 컨테이너의 stdout/stderr를 가져옵니다.
라인 수 지정, Follow(실시간 스트리밍), Timestamps, Previous 같은 옵션은 제공하지 않습니다. 실시간 스트리밍이 필요한 경우 명령 실행 탭의 실시간 모드를 사용하세요.
Step 1: 로그 탭 열기
먼저 로그를 확인할 서비스를 선택합니다.
- [서비스 관리] 페이지에서 원하는 서비스를 선택합니다.
- Operate 단계를 클릭합니다.
- 운영 모달에서 로그 조회 탭을 선택합니다.
로그 탭에 접근하려면 해당 서비스에 대한 운영 권한이 필요합니다.
Step 2: 대상 선택
Kubernetes
- Pod 선택 드롭다운에서 대상 Pod를 선택합니다.
- Pod 상태 아이콘은 외부 콜백을 통해 표시됩니다. 상태 색상은
running은 파란색,pending은 주황색,failed/error는 빨간색, 그 외 상태는 회색으로 표시됩니다.
Docker/Podman
- 컨테이너 선택 드롭다운에서 대상 컨테이너를 선택합니다.
- 컨테이너 이름과 이미지를 확인합니다.
Step 3: 로그 조회
- 대상을 선택한 뒤 로그 조회 버튼을 클릭합니다.
- 로그 뷰어에 결과가 표시됩니다.
- 결과를 비우려면 초기화 버튼을 클릭합니다.
로그 뷰어 UI
- 대상 선택: Pod/컨테이너 드롭다운
- 로그 조회 버튼: 로그 조회/새로고침
- 초기화 버튼: 로그 화면 클리어
- 로그 영역: 모노스페이스 폰트, 다크 테마
로그 뷰어 특징
- 다크 테마: 가독성 높은 어두운 배경
- 모노스페이스 폰트: 코드/로그 가독성
- 스크롤: 대량 로그 스크롤 지원
- 선택 및 복사: 텍스트 선택하여 복사 가능
- 브라우저 검색:
Ctrl+F로 키워드를 검색할 수 있습니다. 별도의 로그 레벨 필터, 정규표현식 검색 기능은 제공하지 않습니다.
로그 분석 기법
로그를 효과적으로 분석하면 문제를 빠르게 해결할 수 있습니다.
에러 로그 찾기
로그에서 이런 패턴을 찾아보세요. 대부분의 문제는 이런 키워드로 시작됩니다.
ERROR: Connection refused to database
[ERROR] Failed to bind to port 8080
Exception in thread "main"
panic: runtime error
로그 뷰어에서 Ctrl+F를 눌러 ERROR, Exception, panic 같은 키워드를 검색하면 문제를 빠르게 찾을 수 있습니다.
로그 레벨 이해하기
로그 레벨은 메시지의 중요도를 나타냅니다.
- ERROR: 즉시 대응이 필요한 심각한 오류입니다.
- WARN: 당장은 문제없지만 주의가 필요한 경고입니다.
- INFO: 정상적인 운영 정보입니다.
- DEBUG: 개발자를 위한 상세 디버그 정보입니다.
주요 확인 포인트
문제 유형에 따라 확인해야 할 내용이 다릅니다.
- 앱 시작 실패: 초기화 에러, 포트 바인딩 실패, 의존성 연결 문제
- 요청 처리 오류: HTTP 5xx 에러, 스택 트레이스
- 성능 문제: 응답 시간 지연, 타임아웃, 커넥션 풀 고갈
- 메모리 문제: OOM(Out of Memory), GC 관련 로그
실제 사용 시나리오
시나리오 1: 배포 후 서비스 시작 확인
목적: 새로운 버전 배포 후 정상 시작 여부 확인
- Operate → 로그 조회 탭 열기
- 새로 생성된 Pod 선택
- 로그 조회 클릭
- 확인할 메시지:
Starting application...
Server started on port 8080
Database connection established
Application ready
시나리오 2: 요청 실패 원인 분석
목적: API 호출 실패의 원인 파악
- 실패가 발생한 Pod 선택
- 로그 조회 클릭
- 에러 패턴 검색(
Ctrl+F):Exception,Error,Failed- HTTP 상태 코드 (500, 502, 503)
- 스택 트레이스 분석
시나리오 3: 재시작된 Pod 디버깅
목적: 재시작된 Pod의 문제 원인 파악
Kubernetes에서 Pod가 재시작된 경우:
- Pod 선택 후 로그 조회 클릭
- 애플리케이션 시작 로그에서 초기화 실패 원인 확인
CrashLoopBackOff상태인 경우 최근 로그에서 panic, exception 검색- 추가 이벤트는 파드 목록 탭에서 해당 Pod의 expand 행을 펼쳐 확인합니다(별도의 "이벤트 탭"은 없습니다).
로그 기반 문제 해결
일반적인 에러 패턴
Connection refused: DB나 서비스 연결이 실패했습니다. 의존 서비스 상태를 확인하세요.Port already in use: 포트가 충돌합니다. 포트 설정을 확인하세요.OutOfMemoryError: 메모리가 부족합니다. 리소스 limit을 증가시키세요.Permission denied: 권한이 부족합니다. 파일이나 디렉토리 권한을 확인하세요.No such file or directory: 파일이 누락되었습니다. ConfigMap이나 Volume 마운트를 확인하세요.
Java 애플리케이션
// 스택 트레이스 확인
java.lang.NullPointerException
at com.example.MyClass.method(MyClass.java:42)
// 해결: 해당 라인의 null 체크 추가
Node.js 애플리케이션
// 처리되지 않은 예외
UnhandledPromiseRejectionWarning
Error: connect ECONNREFUSED 127.0.0.1:5432
// 해결: DB 연결 설정 확인
Python 애플리케이션
// Import 에러
ModuleNotFoundError: No module named 'requests'
// 해결: requirements.txt에 의존성 추가
로그 다운로드
로그 저장
- 로그 영역에서 텍스트 전체 선택 (Ctrl+A)
- 복사 (Ctrl+C)
- 텍스트 편집기에 붙여넣기
.log또는.txt파일로 저장
로그 공유
- 팀원에게 문제 공유 시 관련 로그 발췌
- 민감 정보 (비밀번호, 토큰) 제거 후 공유
문제 해결
로그가 표시되지 않음
- Pod가 Pending 상태: Pod가 Running 상태가 될 때까지 대기하세요.
- 컨테이너가 stdout으로 출력 안함: 애플리케이션 로그 설정을 확인하세요.
- 권한 부족: 서비스 운영 권한을 확인하세요.
연결 끊김
- 네트워크 불안정: 새로고침 또는 모달을 다시 열어보세요.
- 세션 타임아웃: 재로그인 후 재시도하세요.
로그 양이 많음
- 브라우저 검색 활용:
Ctrl+F로 에러 키워드를 검색해 범위를 좁힙니다. - 시간 범위 제한: 최근 발생 시점에 집중합니다.
베스트 프랙티스
오랜 경험에서 얻은 로그 분석 노하우를 공유합니다.
효율적인 로그 분석
아래 순서대로 분석하면 대부분의 문제를 빠르게 파악할 수 있습니다.
- 최신 로그부터 확인: 가장 최근 에러가 근본 원인일 가능성이 높습니다.
- 에러 체인 추적: 첫 번째 에러에서 시작해서 연쇄 에러의 순서를 파악합니다.
- 타임스탬프 활용: 문제 발생 시점과 로그 시간을 대조하여 범위를 좁힙니다.
- 컨텍스트 파악: 에러 전후 로그를 읽어 전체 상황을 이해합니다.
로그 품질 개선 (개발자용)
좋은 로그는 디버깅 시간을 크게 단축시킵니다.
- 적절한 로그 레벨 사용: ERROR, WARN, INFO, DEBUG를 상황에 맞게 구분합니다.
- 구조화된 로그: JSON 형식으로 출력하면 파싱과 검색이 용이합니다.
- 컨텍스트 포함: 요청 ID, 사용자 ID 등 추적 정보를 포함합니다.
- 민감 정보 제외: 비밀번호, 토큰은 마스킹하여 보안을 유지합니다.
로그에 비밀번호, API 키, 개인정보 등이 포함되지 않도록 주의하세요. 로그는 여러 사람이 볼 수 있습니다.